
Autonomous navigation in unknown environment using sliding mode SLAM and genetic algorithm


Abstract
In this paper, sliding mode control is combined with the classical simultaneous localization and mapping (SLAM) method. This combination can overcome the problem of bounded uncertainties in SLAM. With the help of genetic algorithm, our novel path planning method shows many advantages compared with other popular methods.
Keywords
1. Introduction
1.1. Autonomous navigation in unknown environment
Autonomous navigation (AN) has three jobs[1].
1. Perception: Mapping from signal to information is the perception of AN[2]. Its algorithms can use human thought[3], intelligent methods[4], optimization[5], probability methods[6], and genetic algorithms[7].
2. Motion planning: It has three classes, namely graph methods such as a roadmap[8], random sampling[9], and grid[10].
3. Localization and mapping: In unknown environments, sensors, actuators, and maps may have big uncertainties.
Path planning (PP) can be performed under the following conditions:
(1) The environment is known. PP is an optimization problem[11–13].
(2) The environment is partially known. PP can find new objects during navigation[14,15].
(3) The environment is totally unknown. PP depends on the navigation and has a recursive solution[16–18].
Simultaneous localization and mapping (SLAM) can be used in unknown environments[19] or in partially unknown environments[20]. SLAM[21] uses the current position to construct a map, and it can be classified into feature-based[22], pose-based[23], appearance-based[24], and variants[25].
The most popular SLAM uses Kalman filter[21] for Gaussian noise. Nonlinear SLAM uses extended Kalman filter (EKF)[26], where the noise assumptions are not satisfied[27]. EKF-SLAM applies linearization[28].
1.2. Related work
Few AN uses SLAM. Visual SLAM uses several cameras[29]. AN can use both SLAM and GPS signals[30]. Robots can avoid moving obstacles using neural networks[31]. Swarm optimization helps robots follow an object[32]. Neural networks help robots construct the navigation path[33]. The optimal path is considered in the sense of trajectory length, execution time, or energy consumption.
Genetic algorithms (GA) have been developed recently[34,35]. They are easy to use for optimization in non-deterministic cases[36], uncertainty models[37], and robust cases[38]. GA can be in form of ant-based GA[39,40], cell decomposition GA[41], potential field GA[42], ant colony[43], and particle swarm optimization[44]. Finite Markov chain is a theory tool for GA[45,46].
1.3. Our work
In this paper, we try to design AN in an unknown environment in real time. The contributions are as follows:
(1) Sliding mode SLAM: The robustness of this SLAM is better than other SLAM models in bounded noise.
(2) GA SLAM: We use roadmap PP and GA to generate the local optimal map.
(3) Comparisons and simulations with other SLAM models were made by using a mobile robot[47].
2. Sliding mode slam
SLAM gives the robot position and environment map at the same time. At time k, the state is
Xk has two parts: the robot
where f () is the robot dynamics, Wk is the noise, and uk is the robot control. Since
Zk is defined as the position between the robot and the landmark, whose model is
where h() is the geometry and vik is the noise. Here, wk and vik are not Gaussian noises. We assume wk and vik are bounded.
To estimate xk in Equations (1) and (2), EKF is needed. We linearize the state model in Equation (1) and the observation model in Equation (2) as
where
Prediction. The estimation
where R1 is the covariance of Wk, R1 = E {[Wk – E (Wk)] [Wk – E (Wk)]T}.
Correction. The new state is based on predicted states, landmarks, and current observations:
The motivations of using sliding mode modification to the EKF bases SLAM based are the following:
(1) The noises wk and
(2) There are linearization error terms,
We use the sliding mode method to estimate the robot state
Sliding modes have a number of attractive features, and thus have long been in use for solving various control problems. The basic idea behind design of system with sliding mode is the following two steps: (1) a sliding motion in a certain sense is obtained by an appropriate choice of discontinuity surfaces; and (2) a control is chosen so that the sliding modes on the intersection of those discontinuity surface would be stable. A general class of discontinuous control u (x, t) is defined by the following relationships:
where the functions u+ (x, t) and u– (x, t) are continuous.
The function S (x) is the discontinuity surface (subspace). The objective of the sliding mode control is to design some switching strategy of the continuous control u+ (x, t) and u– (x, t), such that
In this paper, the sliding surface is defined by the SLAM estimation error as
Here, the discontinuity surface is e (k) = [e1… en]. We consider the following positive definite function,
where P is diagonal positive definite matrix, P = PT > 0. The derivative of V is
The motion e (k) satisfies
where
because P = diag {pi}, pi > 0, and ei × sgn (ei) = |ei|
Thus,
The classical SLAM in Equations (4) and (5) is modified by the sliding surface in Equation (11). The sliding mode control can be regarded as a compensator for Equation (4):
where ρ is a positive constant. The correction step is the same as EKF in Equation (5). The sliding mode SLAM is shown in Figure 1. Here, the estimation error, e (k), is applied to the sliding surface to enhance the robustness in the prediction step with respect to the noise and disturbances.
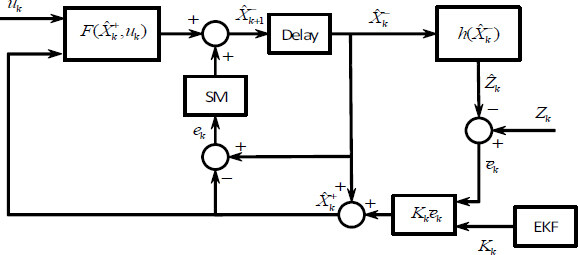
Figure 1. Sliding mode simultaneous localization and mapping.
It is the discrete-time version of Equation (6). We give the stability analysis of this discrete-time sliding mode SLAM at the end of this section.
For the mobile robot, the sliding mode SLAM can be specified as follows. We define a critical distance dmin to limit the maximal landmark density. It can reduce false positives in data association and avoid overload with useless landmarks. If the new landmark is far from the other landmarks on the map, then the landmark is added; otherwise, it is ignored. If the distance between the new landmark Xk+1 = [xm+1,ym+1] and the others is bigger than dmin, it should be added into xk, i.e.,
It can be transformed into an absolute framework as
The nonlinear transformation function T also applies to the uncertainties. We approximate the transformation T by the linearization. Pk can be expressed as
where
with
For the motion part, we use the Ackerman vehicle model [49]
where Wk is the process noise, vk is the linear velocity, αk is the steering angle, Tk is the sample time, and ba is the distance between the front and the rear wheels.
At the beginning of map building, the vector
where x, y, z, and m are defined in Equations (1) and (2),
We exploit the same property in the sliding SLAM. The landmarks with fewer corrections are removed from the state vector.
where
This sliding SLAM algorithm is given in the following algorithm.
The discrete-time sliding mode SLAM in Equation (19) can be written as
where
The correction step for
where
The error dynamic of this discrete-time sliding mode observer is
where
The next theorem gives the stability of the discrete-time sliding mode SLAM.
Theorem 1If the gain of the sliding mode SLAM is positive, then the estimation error is stable, and the estimation error converges to
where
Proof 1Consider the Lyapunov function as
where Pk+2 is the prior covariance matrix in Equation (21), and Pk+2> 0. From Equation (22),
Because
where
The second term of Equation (25) is
where Kk is the gain of EKF in Equation (5). In view of the matrix inequality
which is valid for any X, Y ∊
We apply the sliding mode compensation in Equation (20) to the second term of Equation (27):
where lij are the elements of the matrix
Thus, the second term of Equation (27) is negative.
The first term on the right side of Equation (25) has the following properties:
(I - KkCk) is invertible, and we have
According to EKF,
Thus,
By the following matrix inversion lemma,
where Γ and Ω are two non-singular, matrices,
Using Equation (32) and defining L = (1 –KkCk),
Now,
Hence,
Combining the last term of Equation (29) with the first term on the right side of Equation (25),
where
Combining Equation (26), the first term of Equation (29), and Equation (34),
Thus,
where
then Vk+1– Vk ≤ 0, ||e (k)|| decreases. Thus, ||e (k)|| converges to Equation (23).
3. Genetic algorithm and slam for path planning
Path planning is one key problem of autonomous robots. Here, the map is built by the sliding mode SLAM:
• The obstacle set is defined by Bobs(t).
• The position is xr(t), Bfree(t) = B\Bobs(t).
• The path planning is f (x (t), xs, xT),xs = xr(t).
The previous map is Bfree(t), which requires the path f(x(t),xs,xT).
We assume the previous map is obstacle-free, the initial point is xs, the target point is xT ∊ B,
the obstacle is
D is defined as the search space. We use the GA to find an optimal trajectory f (x, xs, xT), such that
Here, we use stochastic search for GA, and each iteration includes: reproduction or selection, crossing or combination, and mutation. The population is
(1) Every chromosome
(2) Crossing the chromosomes. An intersection in
where
(3) Mutation. It replace a number of chromosomes by chromosomes in D.
The mutation operation is calculated by the fitness of each chromosome,
Euclidean distance. The total fitness is
An optimal solution pM in D is mutated by
In the mutation operation, an optimal solution with pM = 1 is a global solution if n → ∞. To prove the convergence, we use a Markov chain, as shown in Figure 2. Each chromosome can move from Qij to the state Qi(j+1). The moving probability is ρji,ik > 0, i = 1, 2, …,n, k,j = 1, 2, …,m.
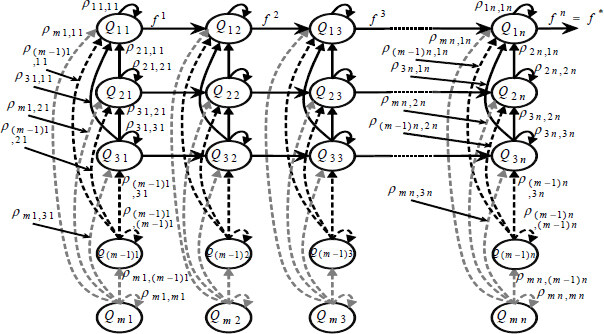
Figure 2. Roadmap genetic algorithm model as a finite Markov chain.
The operators, selection, crossing, and mutation create P(k) with pk. It preserves the best chromosomes of P(k – 1). P(k + 1) in the population P(k) can be regarded as the Markov transition:
Theorem 2If GA for the roadmap is an elitist process, then the probability of p*in D is exponential.
Proof 2The iteration Q1 is changed with the chromosomes when genetic process is elitist,
where n is the size of the population. If for all α, β ∊ D, there is 0 < τ ≤ msuch that Hτ (α, β) ≥ ∊ > 0, then
This implies that, given certain state Qt, the probability of transition in time t between t and t + m is at least ∊,
Without loss of generality, the transition in the iteration k + 1 is
Using Equation (42), we have
where
Since 0 < ∊ ≤ 1, the algorithm converges exponentially to p* in: population size n and iteration number k.
The algorithm of the SLAM-based roadmap GA for the path planning is as follows.
4. Autonomous navigation
Our AN uses both sliding mode SLAM (Algorithm 1) and the roadmap GA method (Algorithm 2). The autonomous navigation algorithm is:
The PP needs the map, robot position, and target. This information is given by the sliding mode SLAM algorithm. When the algorithm falls into a local solution, we use the ComputeOutsideLocal function to provide another Sn which is outside the local zone.
5. Comparisons
In this section, we use several examples to compare our method with the three other recent methods: the polar histogram method for path planning[50], the grid method for path planning[51], and SLAM with extended Kalman filter [52].
5.1. Simulations
The following simulations were implemented in partially unknown and completely unknown environments. The size of the environments was 100 m × 100 m, in which a solution was sought to find a trajectory from the initial point xs to the target point xT. The sliding mode gains were selected as ρ = diag ([0.1, …, 0.1]).
In the partially unknown environments, Bobs(0) ≠ θ. The path planning solution p* was partial because the environment Bobs(t) was variant in time. Figure 3 shows a partial solution p* from an initial point xs to the objective point xT for the partially unknown environment. Figure 4 shows the overall result of the robot navigation from point xs to point xT with the robust SLAM algorithm combined with the GA.

Figure 3. Sliding mode simultaneous localization and mapping.
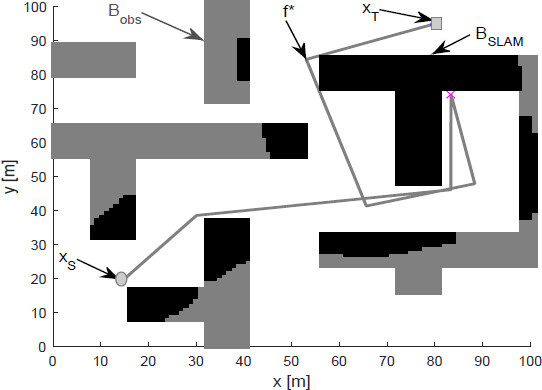
Figure 4. Autonomous navigation using sliding mode simultaneous localization and mapping and genetic algorithm method.
Here, the SLAM algorithm was used to construct the environment and find the position of the robot. At the beginning of navigation in the partially unknown environment, there was a planned trajectory of navigation through the GA algorithm; however, if an obstacle was found in the planned trajectory, the GA algorithm needed to be used to search for a new trajectory within the built environment by the SLAM, BSLAM. The planned trajectory belonged to the set of obstacles that prevent reaching the goal, p* (Bobs(t); therefore, it was necessary to look for a new trajectory using RGA that allowed reaching the goal.
For the completely unknown environments, Bobs(0) = θ. In these environments, the SLAM algorithm was required to know the environment BSLAM and the position of the robot; in this way, when an obstacle was found that contained the planned trajectory, a new trajectory with the GA algorithm was searched on the map
BSLAM until the target point was reached the results obtained are shown in Figure 5. When we used the polar histogram method for path planning [50], only the local solutions could be found [Figure 6].
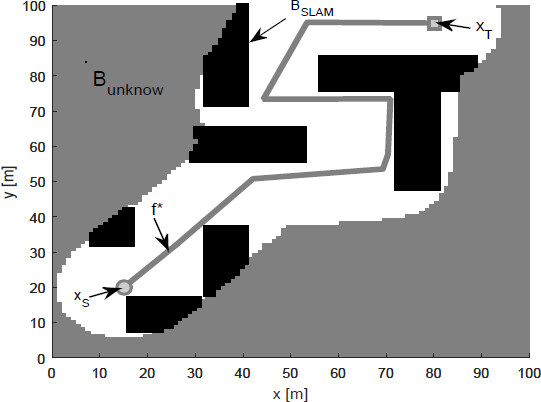
Figure 5. Sliding mode simultaneous localization and mapping and genetic algorithm in complete unknown environment.
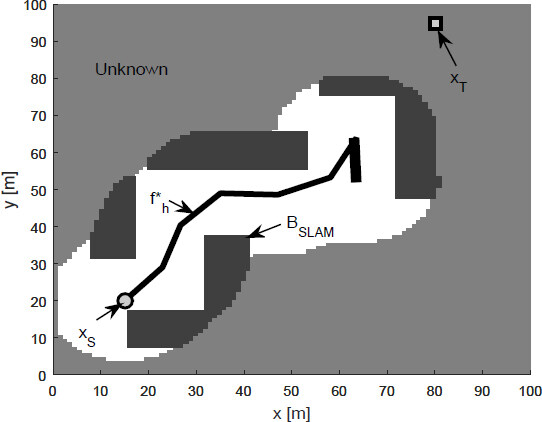
Figure 6. Polar histogram method in complete unknown environments.
Now, we compare the path lengths with the polar histogram method. The following density of the obstacles give the navigation complexity. The environment is free of obstacles when dobs = 0. The whole environment is occupied by the obstacles when dobs = 1. The index for the trajectory error is
We use the averages of the path length. The obstacles density is defined as
The path length is defined as
The averages of the path lengths of our RA and the polar histogram are shown in Figure 7. When the density of obstacles was bigger, the path length of the polar histogram grew more quickly than that of ours. When the obstacle density dobs was 0.3, E[lsub, Navigation1] = 1.053, E[lsub, Navigation2] = 1.152.
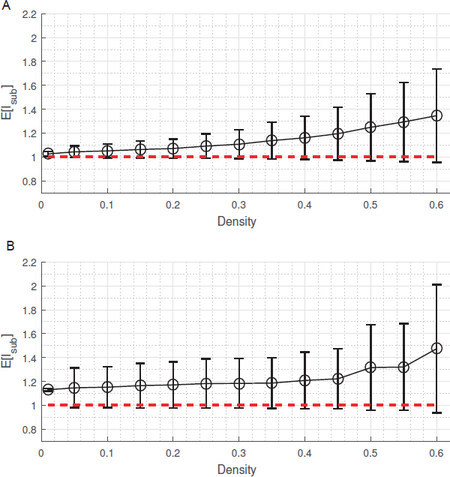
Figure 7. The average path length: (A) sliding mode simultaneous localization and mapping and genetic algorithm; and (B) polar histogram.
Next, we compare our method with the grid method[51]. The comparison results are shown in Figure 8. For the task of navigating the robot or system in partially unknown or completely unknown environments, the SLAM algorithm was used to construct the environment and know the position of the robot. At the beginning of navigation in the partially unknown environment, there was a planned trajectory of navigation through the GA algorithm; however, if an obstacle were found in the planned trajectory, the GA algorithm needed to be used to search for a new trajectory within the built environment by the SLAM, BSLAM.

Figure 8. Sliding mode simultaneous localization and mapping (gray) and grid method (black)
The size of the environments was 100m× 100 m, in which a solution was sought to find a trajectory from the initial point xs to the target point xT.Figure 9 shows a path planning based on the proposed methods to find a solution f*. Here, 60 local targets were generated xi with the search space D generated by the trajectories of the local targets that do not intersect with the set of obstacles; thus, it became an optimization problem to find an optimal path.
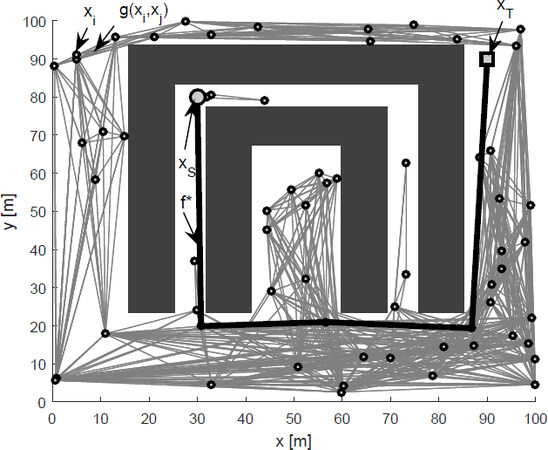
Figure 9. Sliding mode simultaneous localization and mapping based path planning (bold) and grid method (gray).
In an environment with previously generated obstacles of 100 m × 100 m, 120 possible targets were randomly generated xi; therefore, the search space D would be all trajectories g(xi,xj) that do not intersect with the set of obstacles, where the roadmap genetic algorithm solved the problem of optimization to find a solution to the problem of path planning. For the problem presented above, we found that the proposed algorithm converged in 40 iterations. For these results, 100 tests were performed for each number of iterations and, as shown in Figure 10, the roadmap genetic algorithm converged with greater probability within 40 iterations.
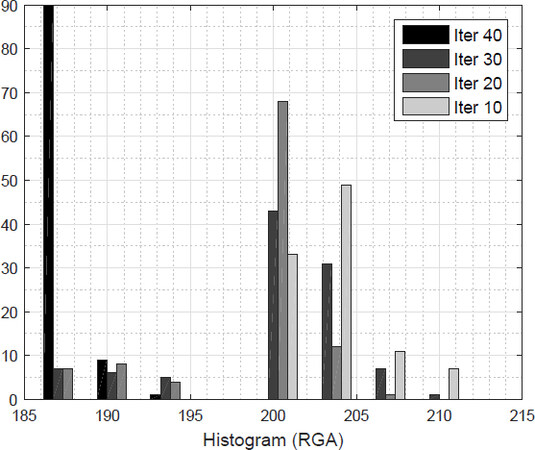
Figure 10. Performance of the genetic algorithm.
5.2. Application
The Koala mobile robot by K-team Corporation 2013 was used to validate our sliding mode SLAM. This mobile robot has encoders and one laser range finder. The position precision is less than 0.1 m.
The objective of this autonomous navigation is to force the robot to return to the starting point. The sliding mode SLAM was compared with SLAM with extended Kalman filter (EKF-SLAM) [52]
The initial covariance matrices are zero. The parameters of the algorithm are
Since the robot moves in the environment with bounded noise (see Figure 11), the noises are not Gaussian. Two different conditions are considered: (1) Koala robot pre-processes off-line the sensors data to reduce 90% noises; and (2) the computer uses sliding mode SLAM on-line.

Figure 11. The environment of the autonomous navigation.
For the first case, Figure 12 shows that sliding mode SLAM and EKF-SLAM are similar. Both sliding mode SLAM and EKF-SLAM work well for the case with less noise. The robot can return to the starting point, and the map is constructed correctly.
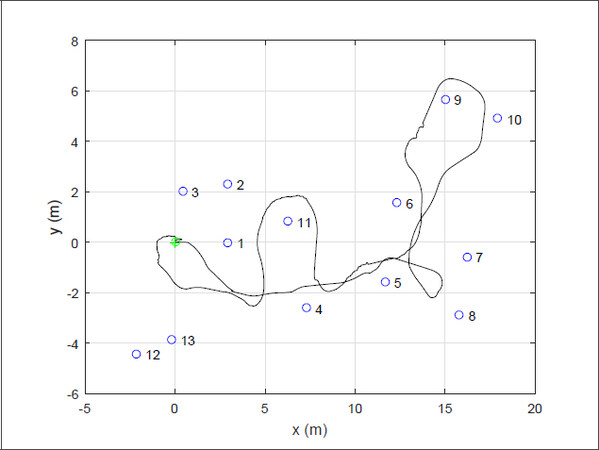
Figure 12. Results of extended Kalman filter simultaneous localization and mapping and sliding mode simultaneous localization and mapping with small noises.
For the second case, Figure 13 gives the results of EKF-SLAM. As can be seen, the robot cannot return to the starting point and the map is not exactly the same as the real one with EKF-SLAM because EKF-SLAM is sensitive to non-Gaussian noises.
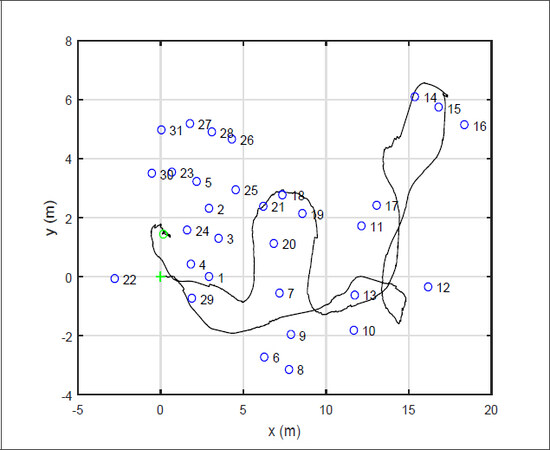
Figure 13. Results of extended Kalman filter simultaneous localization and mapping with noises.
Figure 14 shows the results with SM-SLAM. Under the same bounded noises, SM-SLAM works very well, because of the sliding mode technique.
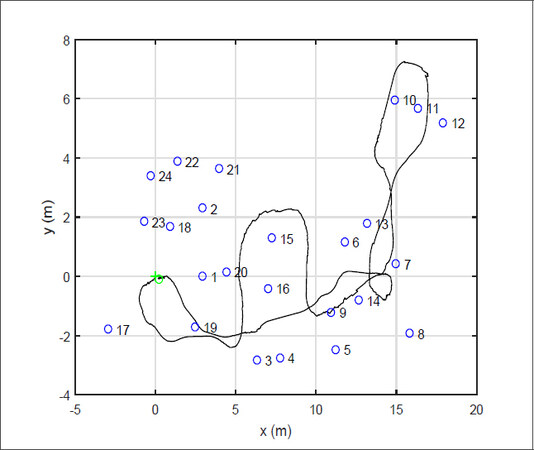
Figure 14. Results of sliding mode simultaneous localization and mapping with noise.
To compare the errors, we define the average of the Euclidean errors as
where NT is the data number;
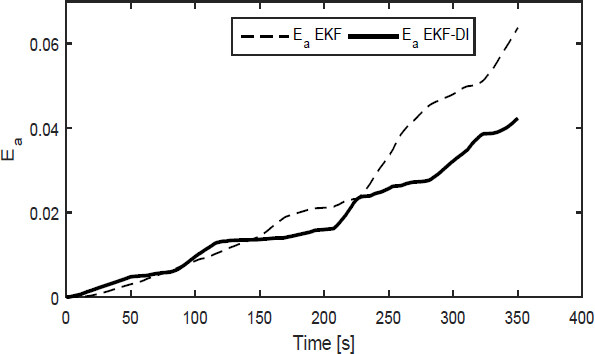
Figure 15. Direction estimation errors of sliding mode simultaneous localization and mapping (SLAM) and EKF-SLAM. EKF: Extended Kalman filter.
6. Conclusion
Navigation in unknown environments is a big challenge. In this paper, we propose sliding mode SLAM with genetic algorithm for path planning. Both sliding mode and GA can work in unknown environments. Convergence analysis is given. Two examples were applied to compare our model with other models, and the results show that our algorithm is much better in unknown environments.
Declarations
Authors’ contributions
Revised the text and agreed to the published version of the manuscript: Ortiz S, Yu W
Availability of data and materials
Not applicable.
Financial support and sponsorship
None.
Conflicts of interest
Both authors declared that there are no conflicts of interest.
Ethical approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Copyright
© The Author(s) 2021.
REFERENCES
1. Luettel T, Himmelsbach M, Wuensche HJ. Autonomous ground vehicles—concepts and a path to the future. Proceedings of the IEEE 2012;100:1831-39.
2. Galceran E, Carreras M. A survey on coverage path planning for robotics. Rob Auton Syst 2013;61:1258-76.
3. Lowe DG. Distinctive image features from scale-invariant keypoints. Int J Comput Vis 2004;60:91-110.
4. Arel I, Rose DC, Karnowski TP. Deep machine learning-a new frontier in artificial intelligence research. IEEE Comput Intell Mag 2010;5:13-8.
5. Scheirer WJ, de Rezende Rocha A, Sapkota A, et al. Toward open set recognition. IEEE Trans Pattern Anal Mach Intell 2012;35:1757-72.
6. Ramos FT, Kumar S, Upcroft B, et al. A natural feature representation for unstructured environments. IEEE Trans Robot 2008;24:1329-40.
7. Lillywhite K, Lee DJ, Tippetts B, et al. A feature construction method for general object recognition. Pattern Recognition 2013;46:3300-14.
8. Chabini I, Lan S. Adaptation of the A* algorithm for the computation of fastest paths in deterministic discrete-time dynamic networks. IEEE trans Intell Transp Syst 2002;3:60-74.
10. Valencia R, Andrade-Cetto J. Mapping, planning and exploration with Pose SLAM. Berlin: Springer; 2018. pp. 60-84.
11. Wang X, Shi Y, Ding D, et al. Double global optimum genetic algorithm–particle swarm optimization-based welding robot path planning. Eng Optim 2016;48:299-316.
12. Jones M, Peet MM. A generalization of Bellman’s equation with application to path planning, obstacle avoidance and invariant set estimation. Automatica 2021;127:109510.
13. Rehman NU, Kumar K, Abro GeM. Implementation of an autonomous path plan-ning & obstacle avoidance UGV using SLAM. 2018 International Conference on Engineer-ing and Emerging Technologies (ICEET) 2018. pp. 1-5.
15. Zhang X, Zhao Y, Deng N, et al. Dynamic path planning algorithm for a mobile robot based on visible space and an improved genetic algorithm. Int J Adv Robot Syst 2016;13:91.
16. Clemens J, Reineking T, Kluth T. An evidential approach to SLAM, path planning, and active exploration. Int J Approx Reason 2016;73:1-26.
17. Chen Y, Huang S, Fitch R. Active SLAM for mobile robots with area coverage and obstacle avoidance. IEEE ASME Trans Mechatron 2020;25:1182-92.
18. da Silva Arantes M, Toledo C F M, Williams B C, et al. Collision-free encoding for chance-constrained nonconvex path planning. IEEE Trans Robot 2019;35:433-48.
19. Yu W, Zamora E, Soria A. Ellipsoid SLAM: a novel set membership method for simultaneous localization and mapping. Autonomous Robots 2016;40:125-37.
20. Williams H, Browne WN, Carnegie DA. Learned action slam: sharing slam through learned path planning information between heterogeneous robotic platforms. Appl Soft Comput 2017;50:313-26.
21. Dissanayake MWMG, Newman P, Clark S, et al. A solution to the simultaneous localization and map building (SLAM) problem. IEEE Trans Rob Autom 2001;17:229-41.
22. Thrun S, Liu Y, Koller D, et al. Simultaneous localization and mapping with sparse extended information filters. Int J Robot Res 2004;23:693-716.
23. Folkesson J, Christensen HI. Closing the loop with graphical SLAM. IEEE Trans Robot 2007;23:731-41.
24. Ho KL, Newman P. Loop closure detection in SLAM by combining visual and spatial appearance. Rob Auton Syst 2006;54:740-9.
25. Nieto J, Guivant J, Nebot E. Denseslam: simultaneous localization and dense mapping. Int J Robot Res 2006;25:711-44.
27. Sibley G, Matthies L, Sukhatme G. Sliding window filter with application to planetary landing. J Field Robot 2010;27:587-608.
28. Kaess M, Johannsson H, Roberts R, et al. iSAM2: Incremental smoothing and mapping using the Bayes tree. Int J Robot Res 2012;31:216-35.
29. Yang S, Scherer SA, Yi X, et al. Multi-camera visual SLAM for autonomous navigation of micro aerial vehicles. Rob Auton Syst 2017;93:116-34.
30. Weiss S, Scaramuzza D, Siegwart R. Monocular-SLAM–based navigation for autonomous micro helicopters in GPS-denied environments. J Field Robot 2011;28:854-874.
31. Zhu A, Yang SX. Neurofuzzy-based approach to mobile robot navigation in unknown environments. IEEE Trans Syst Man Cybern C Appl Rev 2007;37:610-21.
32. Juang CF, Chang YC. Evolutionary-group-based particle-swarm-optimized fuzzy controller with application to mobile-robot navigation in unknown environments. IEEE Trans Fuzzy Syst 2011;19:379-92.
33. Villacorta-Atienza JA, Makarov VA. Neural network architecture for cognitive navigation in dynamic environments. IEEE Trans Neural Netw Learn Syst 2013;24:2075-87.
34. Song B, Wang Z, Sheng L. A new genetic algorithm approach to smooth path planning for mobile robots. Assem Autom 2016;36:138-45.
35. Zhang Y, Gong D, Zhang J. Robot path planning in uncertain environment using multi-objective particle swarm optimization. Neurocomputing 2013;103:172-85.
36. Karami AH, Hasanzadeh M. An adaptive genetic algorithm for robot motion planning in 2D complex environments. Comput Electr Eng 2015;43:317-29.
37. Pereira AGC, de Andrade BB. On the genetic algorithm with adaptive mutation rate and selected statistical applications. Comput Stat 2015;30:131-50.
38. Tsai CC, Huang HC, Chan CK. Parallel elite genetic algorithm and its application to global path planning for autonomous robot navigation. IEEE Trans Ind Electron 2011;58:4813-21.
39. Zhu Q, Hu J, Cai W, et al. A new robot navigation algorithm for dynamic unknown environments based ondynamic path re-computation and an improved scout ant algorithm. Appl Soft Comput 2011;11:4667-76.
40. Arantes MS, Arantes JS, Toledo CFM, et al. A hybrid multi-population genetic algorithm for uav path planning. Proceedings of the Genetic and Evolutionary Computation Conference. 2016 2016. pp. 853-60.
41. Tuncer A, Yildirim M. Dynamic path planning of mobile robots with improved genetic algorithm. Comput Electr Eng 2012;38:1564-72.
42. Raja R, Dutta A, Venkatesh KS. New potential field method for rough terrain path planning using genetic algorithm for a 6-wheel rover. Rob Auton Syst 2015;72:295-306.
43. Arora T, Gigras Y, Arora V. Robotic path planning using genetic algorithm in dynamic environment. Int J Comput Appl 2014;89:9-12.
44. Roberge V, Tarbouchi M, Labonté G. Comparison of parallel genetic algorithm and particle swarm optimization for real-time UAV path planning. IEEE Trans Industr Inform 2012;9:132-41.
45. Bhandari D, Murthy CA, Pal SK. Genetic algorithm with elitist model and its convergence. Intern J Pattern Recognit Artif Intell 1996;10:731-47.
46. Hu ZB, Xiong SW, Su QH, et al. Finite Markov chain analysis of classical differential evolution algorithm. J Comput Appl Math 2014;268:121-34.
47. K-Team Corporation. Available from: http://www.k-team.com/ [Last accessed on 10 Dec 2021].
48. Souahi A, Naifar O, Makhlouf AB, et al. Discussion on Barbalat Lemma extensions for conformable fractional integrals. Int J Control 2019;92:234-41.
49. Erdman AG, Sandor GN, Kota S. Mechanism design: analysis and synthesis. Upper Saddle River, NJ: Prentice hall; 2001.
50. Wilde N, Kulić D, Smith SL. Learning user preferences in robot motion planning through interaction. 2018 IEEE International Conference on Robotics and Automation (ICRA) 2018. pp. 619-26.
51. Farzan S, DeSouza GN. Path planning in dynamic environments using time-warped grids and a parallel implementation. arXiv.1903.07441 2019.
Cite This Article
Export citation file: BibTeX | RIS
OAE Style
Ortiz S, Yu W. Autonomous navigation in unknown environment using sliding mode SLAM and genetic algorithm. Intell Robot 2021;1(2):131-50. http://dx.doi.org/10.20517/ir.2021.09
AMA Style
Ortiz S, Yu W. Autonomous navigation in unknown environment using sliding mode SLAM and genetic algorithm. Intelligence & Robotics. 2021; 1(2): 131-50. http://dx.doi.org/10.20517/ir.2021.09
Chicago/Turabian Style
Ortiz, Salvador, Wen Yu. 2021. "Autonomous navigation in unknown environment using sliding mode SLAM and genetic algorithm" Intelligence & Robotics. 1, no.2: 131-50. http://dx.doi.org/10.20517/ir.2021.09
ACS Style
Ortiz, S.; Yu W. Autonomous navigation in unknown environment using sliding mode SLAM and genetic algorithm. Intell. Robot. 2021, 1, 131-50. http://dx.doi.org/10.20517/ir.2021.09
About This Article
Copyright

Data & Comments
Data


 Cite This Article 12 clicks
Cite This Article 12 clicks

 Like This Article 13
likes
Like This Article 13
likes







Comments
Comments must be written in English. Spam, offensive content, impersonation, and private information will not be permitted. If any comment is reported and identified as inappropriate content by OAE staff, the comment will be removed without notice. If you have any queries or need any help, please contact us at support@oaepublish.com.