
Adaptive backstepping control of high-order fully actuated nonlinear systems with event-triggered strategy
 0
0Abstract
This paper investigates the problem of adaptive event-triggered fuzzy control for nonlinear high-order fully actuated systems. In this paper, a completely unknown nonlinear function is considered, and its prior knowledge is unknown. To solve this problem, the fuzzy logic system technology is applied to approximate the unknown nonlinear function. In order to save communication resources, a novel high-order event-triggered controller is proposed under backstepping control. With the help of Lyapunov stability theory, it is proved that all signals of the closed-loop system are bounded. Finally, the theoretical results are applied to the robot system to verify their validity.
Keywords
1. INTRODUCTION
With the development of modern society and modern industry, linear system theory has become relatively well-established and sophisticated[1–3]. Many scholars have proposed various powerful analysis tools for linear systems. However, with the progress of science and technology and the improvement of the accuracy of measuring tools, the understanding of the actual system is gradually deepened, and the requirements for its control performance are also increasingly high. Ignoring some objective factors, some practical systems are modeled as linear systems and controller designs are carried out, but the designed controllers have not met the requirements for the control performance of practical systems. In such cases, it is particularly necessary to model some practical systems into nonlinear systems. This includes systems such as unmanned vehicle systems[4], unmanned aerial vehicle systems[5], robot systems, and manipulator systems[6]. Therefore, nonlinear systems have received extensive attention from scholars at home and abroad and have proposed various tools to handle the control problem of nonlinear systems, such as adaptive backstepping control[7, 8], sliding mode control[9], etc. Among them, the combination of backstepping recursive design and adaptive control has produced a large number of excellent results[10–14].
The high-order fully actuated system possesses unparalleled control characteristics compared to other systems. Its fully actuated characteristics enable the elimination of all dynamic characteristics of the open-loop system while establishing new and desired closed-loop dynamic characteristics. About high-order fully actuated systems, there have been some excellent results[15–23]. Among them, The work[19] proposed the direct parametric approach of fully-actuated high-order systems. A constrained cooperative control is proposed[22] for high-order fully actuated multiagent systems with prescribed performance.
Since the beginning of this century, networked control systems[24–29] have been widely used in remote operation, industrial automation, building energy conservation, and other fields. This is due to their low maintenance cost and high flexibility. In the networked control system, the actuator, controller, sensor, and other components transmit information through the shared network channel. Therefore, it is necessary to reduce the occupation of shared communication by single subsystem control to achieve the purpose of saving cost and energy. The traditional sampling control[30–33] is based on the system signal sampling value instead of continuous value and takes different constant values periodically, which has relatively high communication efficiency compared with continuous time control. Sampling control requires information transmission and control update at a conservative fixed frequency regardless of obvious changes in system performance, so it is not suitable for networked control systems with high integration, which leads to the emergence of more efficient control of resource utilization, namely event-triggered control. The key point of the event-triggered control design is to build an event-triggered mechanism. The most basic types are absolute threshold type, relative threshold type, and mixed threshold type. The construction of an event-triggered mechanism depends not only on the system structure but also on the expected control objectives. Even with the increase in system complexity and performance requirements, additional dynamic and online adjustment parameters need to be introduced. Over the past decade, significant progress has been made in the research of event-triggered control for nonlinear systems[34–43].
Inspired by the above excellent results and combined with the reality of the lack of event-triggered control results of the high-order fully activated system, this paper studies the adaptive fuzzy event-triggered control for the high-order fully activated system. The contribution of this paper is reflected in two aspects:
1) For the uncertain high-order fully actuated nonlinear system, the unknown nonlinear function is considered, and the fuzzy logic system (FLS) is used to approximate the nonlinear function without a priori condition of the nonlinear function.
2) The proposed event-triggered scheme for the uncertain high-order fully nonlinear system can effectively eliminate the continuous update of the designed controller, thus saving communication resources.
The organization of this article is arranged as follows. The second section includes problem formulas and preliminary knowledge. The third section introduces an event-triggered controller design scheme. The fourth section shows the simulation. The fifth section is the summary.
Notation
2. PROBLEM FORMULAS AND PRELIMINARY KNOWLEDGE
2.1. Problem statement
Consider the following uncertain high-order fully nonlinear system:
where
Remark 1The above-mentioned high-order fully nonlinear system is the general form of a second-order fully nonlinear system. For practical examples, such as robotic systems, it is no longer necessary to transform a high-order system into a first-order system. Instead, we can deal with it directly.
2.2. Preliminaries knowledge
Assumption 1[37] There are two constants that the control gain functions
Remark 2The above assumption is a common standard condition that ensures the controllability of the uncertain high-order fully nonlinear system. This is derived from modeling real systems, and it makes perfect sense.
Lemma 1[38] The unknown nonlinear continuous function
where
Lemma 2[38] For
Lemma 3[18] Design the matrix
where
3. CONTROLLER DESIGN AND STABILITY ANALYSIS
3.1. Adaptive event-triggered controller design
To facilitate the calculation, we first give some necessary coordinate transformations:
where
Step 1: Let
and
With the help of the notations, one has
Choose virtual controller
The Lyapunov candidate function
where
With the help of FLS and Young's inequality, one gets
where
The adaptive law
Based on (8) and (9), one gets
Step 2: Based on the notations, one has
From (1) and (11), the time derivative of
Choose virtual controller
and (12) can be rewritten as state-space form
where
The Lyapunov function candidate
And similar to the (8), one gets
where
The adaptive update law
Replacing (15) and (16) into (14), one gives
Step k:
Choose virtual controller
The Lyapunov function candidate
And similar to the (8), one gets
where
The adaptive law
Based on (21) and (22), one gives
Step n: In this part, the adaptive HOFA event-triggered controller of the system is constant as
where
From (1), the time derivative of
Choose virtual controller
and (27) can be rewritten as state-space form
where
The Lyapunov function candidate
The FLS is used to approximate nonlinear dynamics and adaptive law are same as (21, 22). And from (24, 25, 26), we have
According to
3.2. Stability analysis
Theorem 1: For the high-order fully actuated nonlinear system (1) under the Assumption 1, the virtual controller (6), (13), (19), (28), the actual controller (24), the adaptive law (9), (16), (22), and the event-triggered mechanism (24, 25, 26) are designed. Then, the following statements hold:
1) All signals in the closed-loop system are bounded.
2) There is a positive constant
Proof: 1) Let
where
which means that all signals are bounded.
2) From
where
4. SIMULATION
In this section, to demonstrate the effectiveness of the designed HOFA event-triggered mechanism, a single-link robot arm simulation is carried out.
Example 1: Consider a single-link robot system whose manipulators with an elastic revolute joint are actuated by a brushed direct current motor that can be given by
where
Obviously, the above system is a second-order system, and the proposed high-order ETC backstepping can be handled directly without transforming it into a first-order state space form. Let
In simulations, the robot system factors are designed as follows:
The design parameters are chosen as
The simulation results are given as follows. Figure 1 represents the response of the state
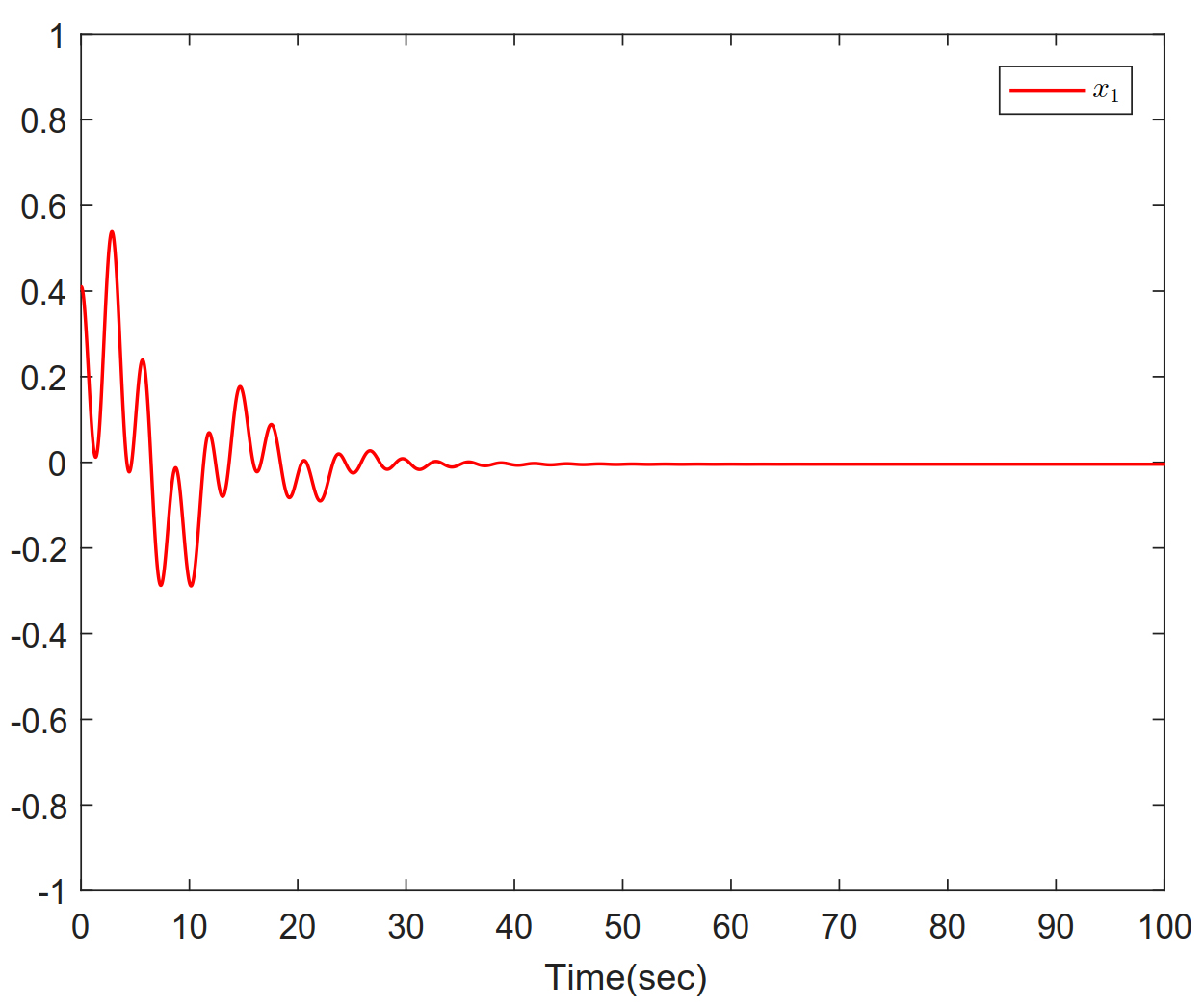
Figure 1. Trajectories of
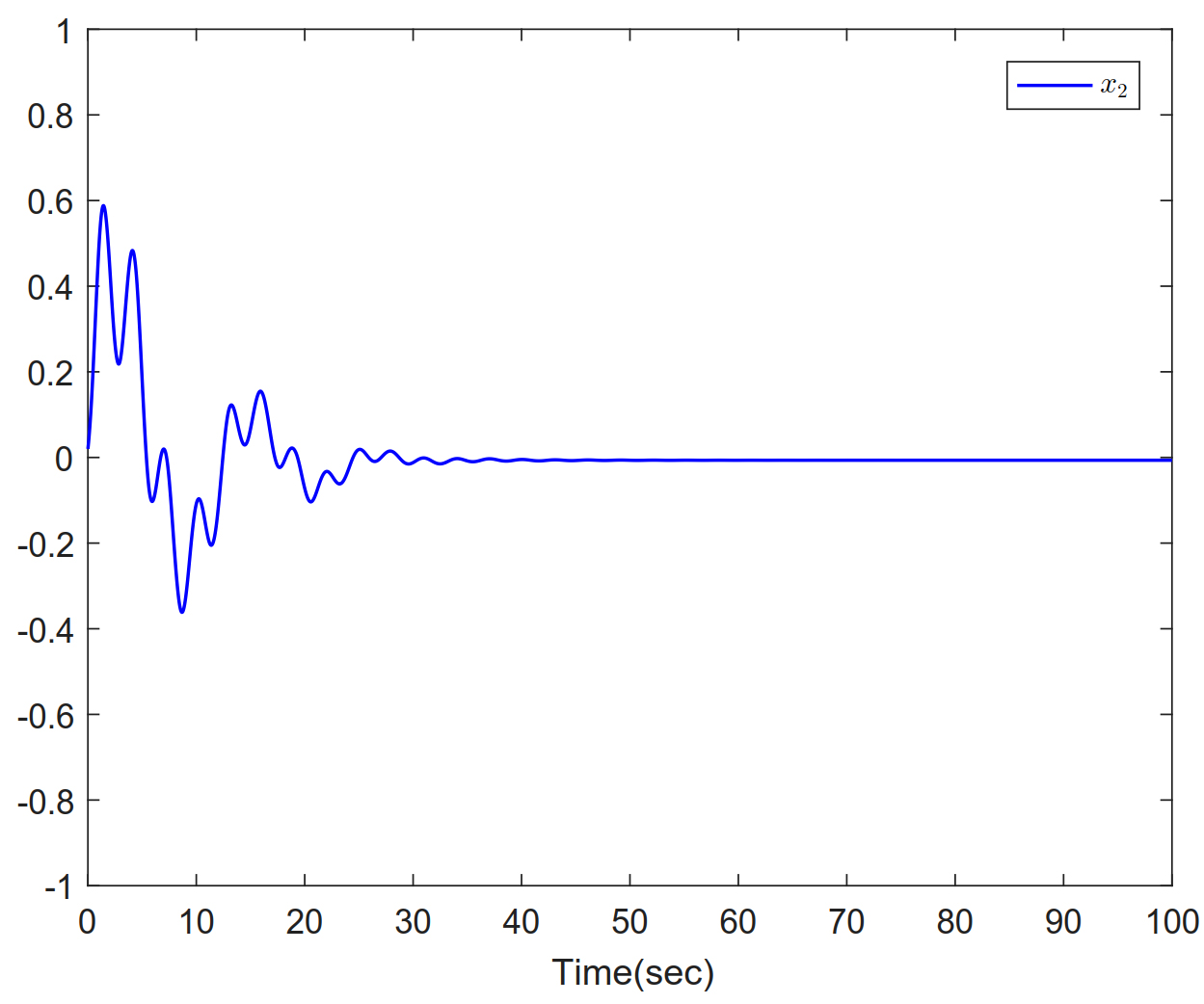
Figure 2. Trajectories of
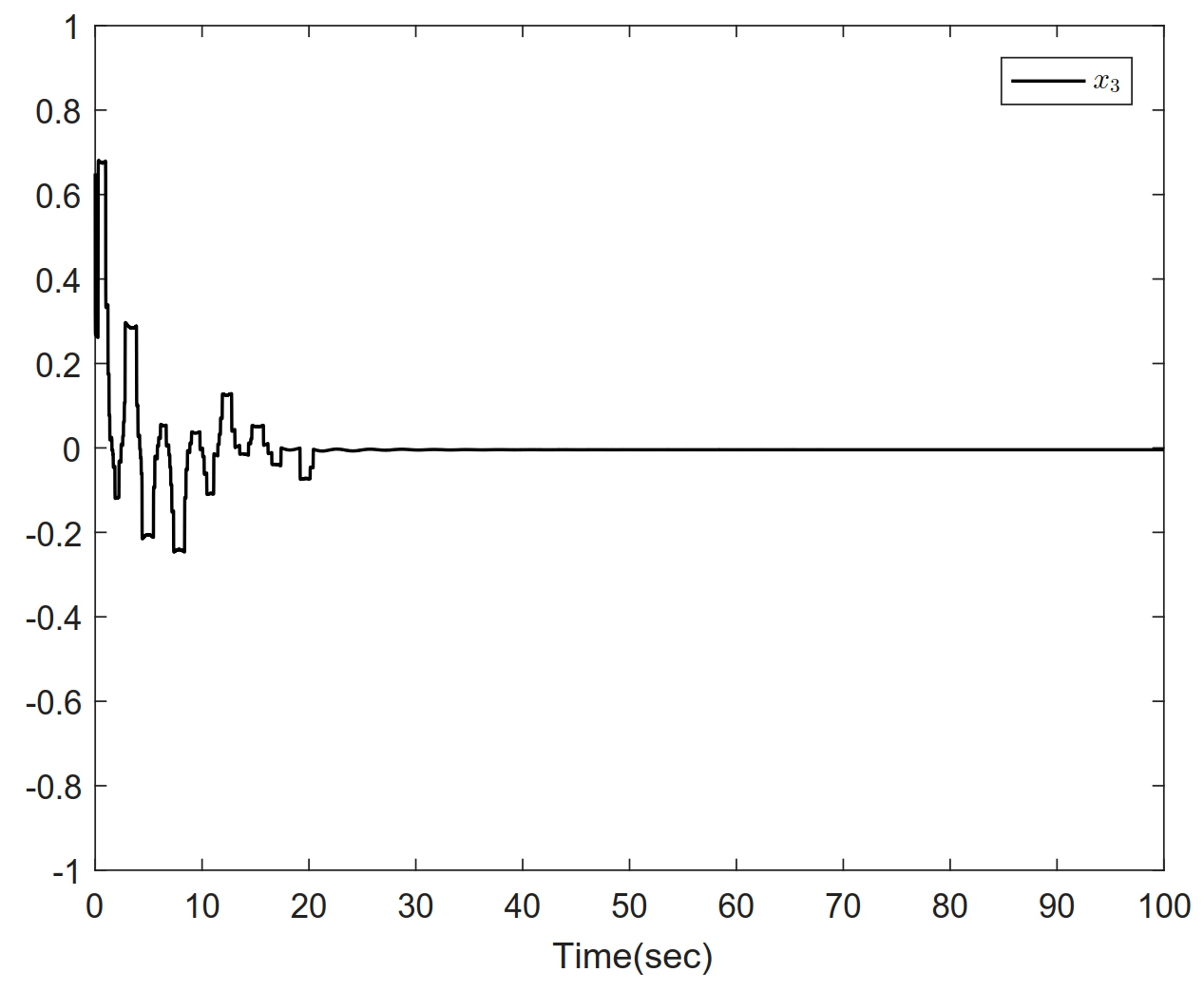
Figure 3. Trajectories of
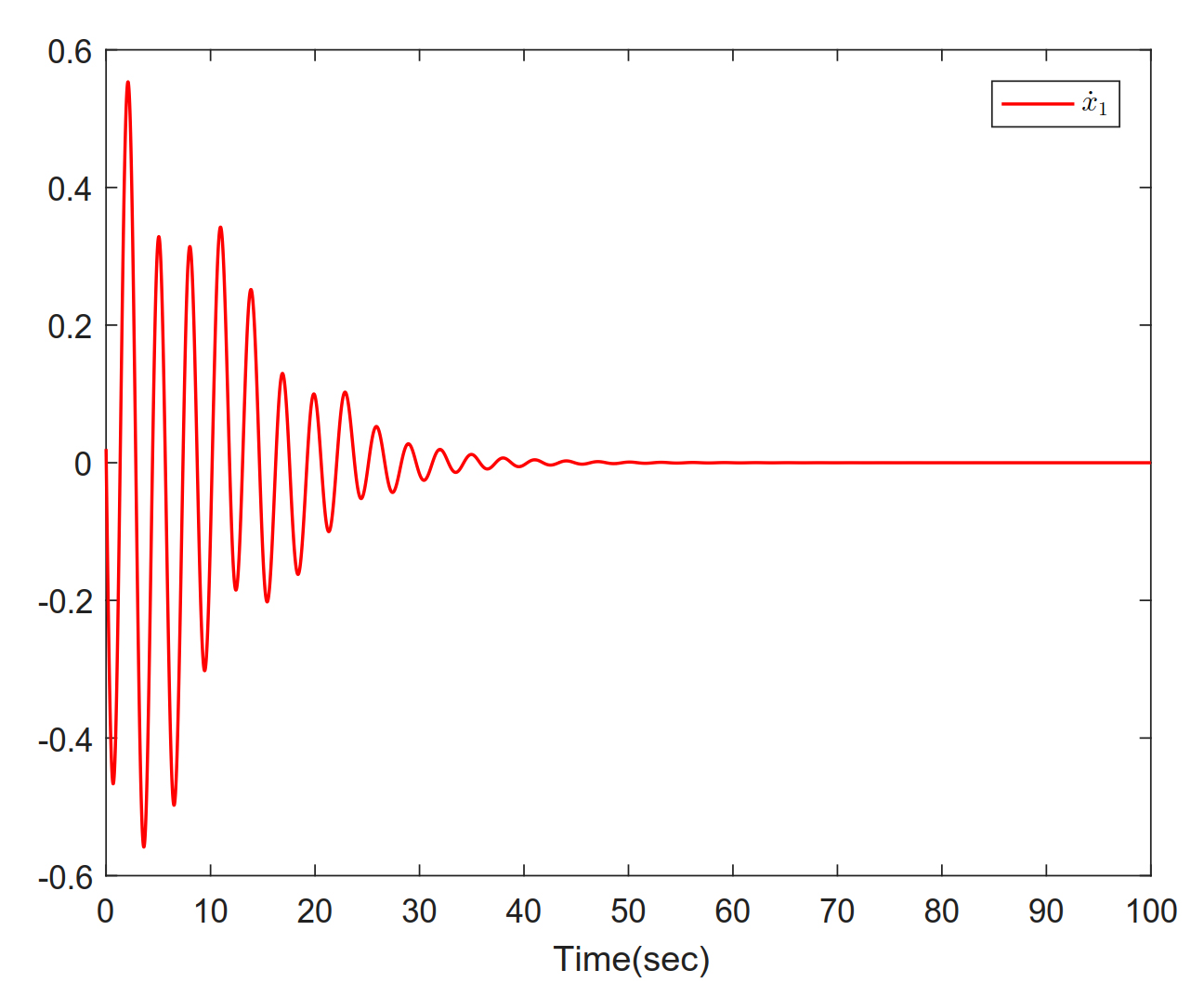
Figure 4. Trajectories of
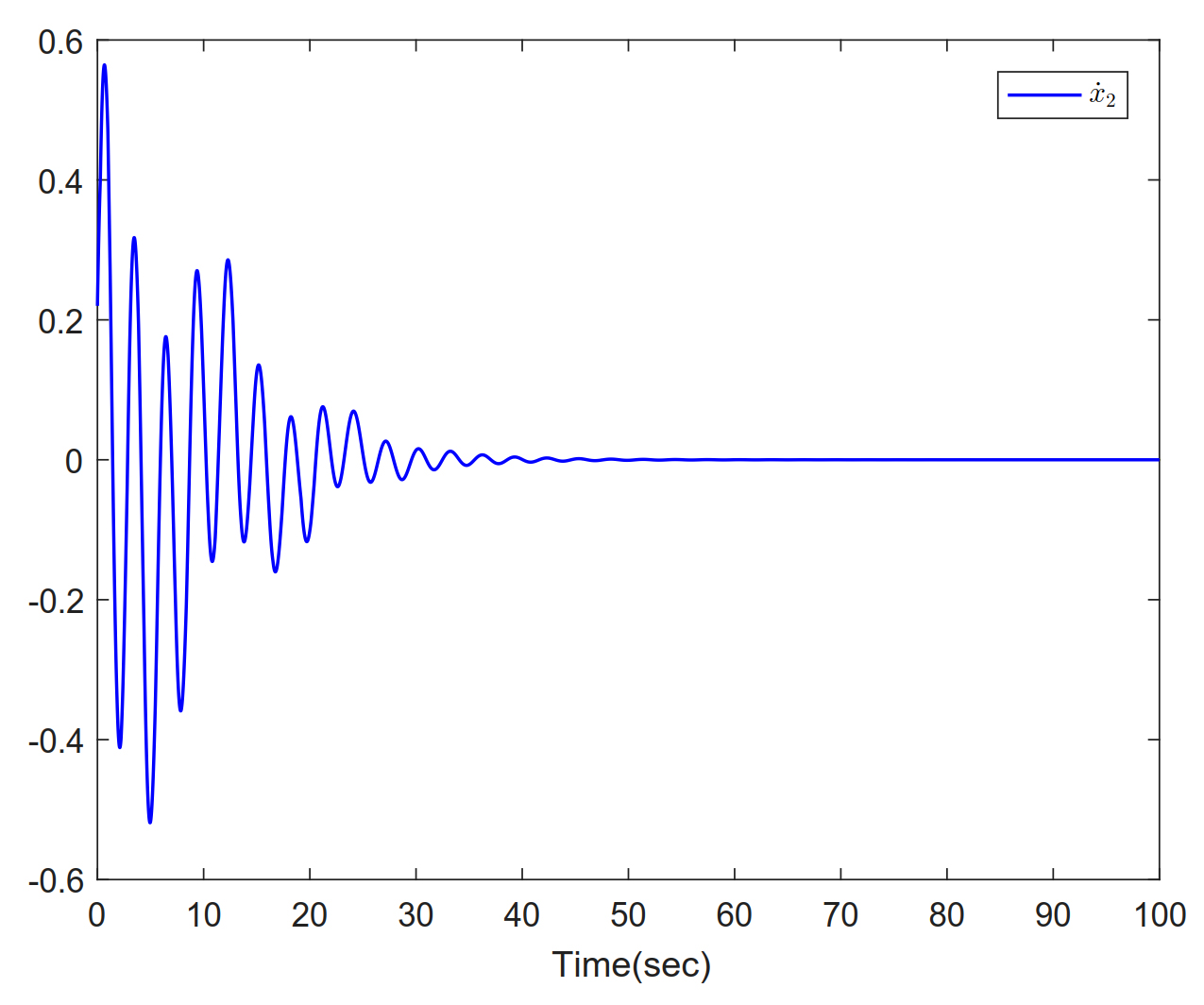
Figure 5. Trajectories of
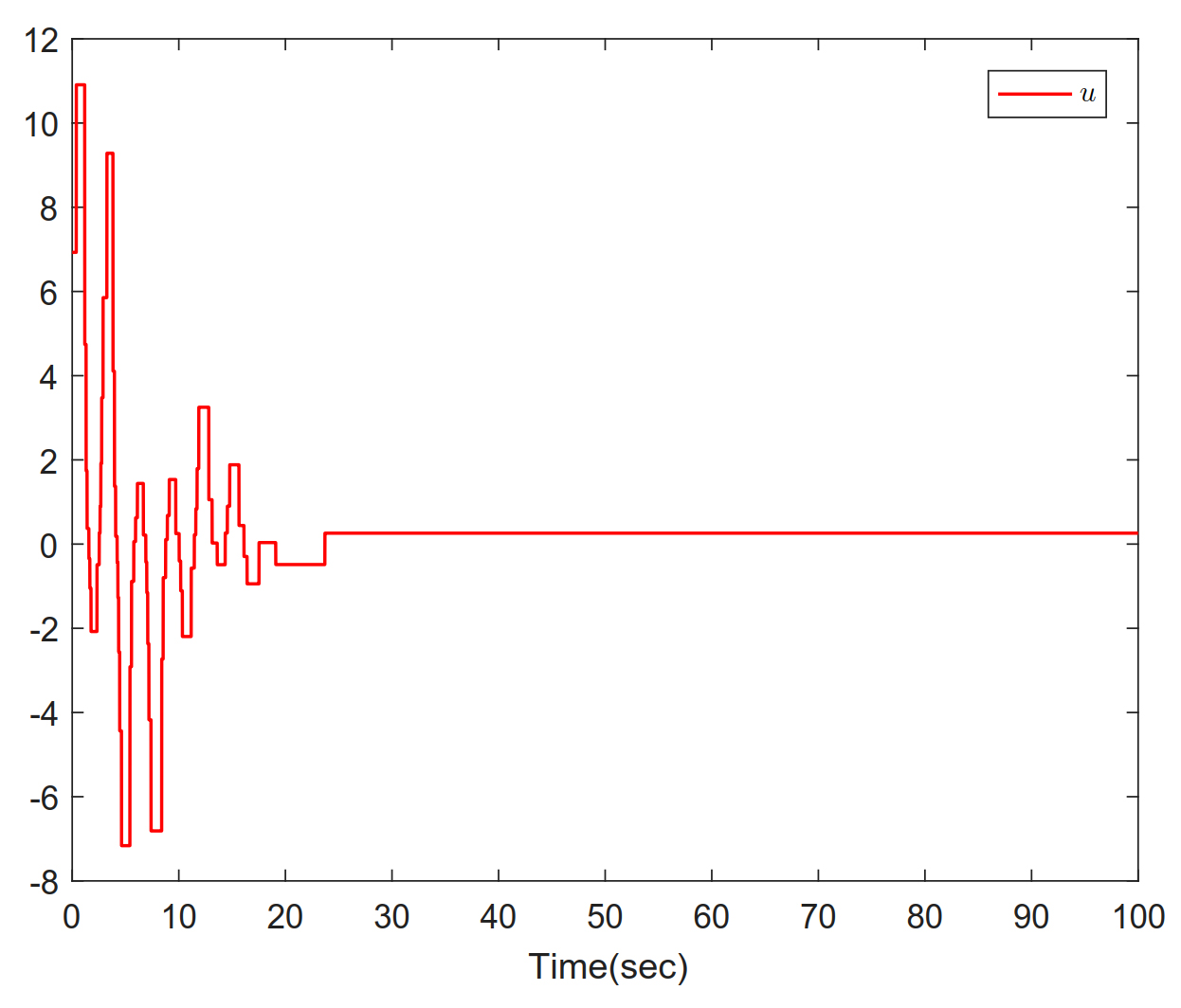
Figure 6. Trajectories of

Figure 7. Inter-event times in Example 1.

Figure 8. Trajectories of adaptive laws

Figure 9. Trajectories of adaptive laws

Figure 10. Trajectories of adaptive laws
5. CONCLUSIONS
In this article, a novel adaptive high-order event-triggered control scheme is proposed for uncertain HOFA nonlinear systems. This scheme not only does not require prior knowledge of the nonlinear function of the system but also saves communication resources by designing the event-triggered scheme. Moreover, the practicality of the control scheme is verified. The future of work will be concerned with the prescribed performance control problem and network attack problem of high-order fully activated nonlinear systems.
DECLARATIONS
Authors' contributions
Made substantial contributions to the conception and design of the study and performed data analysis and interpretation: Yan C, Xia J, Liu X, Yue H
Performed data acquisition and provided administrative, technical, and material support: Xia J, Li C
Availability of data and materials
Not applicable.
Financial support and sponsorship
This work was supported by the National Natural Science Foundation of China under Grants 61973148 and Discipline with Strong Characteristics of Liaocheng University: Intelligent Science and Technology under Grant 319462208.
Conflicts of interest
All authors declared that there are no conflicts of interest.
Ethical approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Copyright
© The Author(s) 2023.
REFERENCES
1. Yuan S, Lv M, Baldi M, Zhang L. Lyapunov-Equation-Based stability analysis for switched linear systems and its application to switched adaptive control. IEEE Trans Automat Contr 2021;66:2250-6.
2. Shi Y, Sun X. Bumpless transfer control for switched linear systems and its application to Aero-Engines. IEEE Trans Circuits Syst Ⅰ 2021;68:2171-82.
3. Zhang K, Zhou B, Jiang H, Liu G, Duan G. Practical prescribed-time sampled-data control of linear systems with applications to the air-bearing testbed. IEEE Trans Ind Electron 2022;69:6152-61.
4. Zhang J, Shao X, Zhang W. Cooperative enclosing control with modified guaranteed performance and aperiodic communication for unmanned vehicles: a path-following solution. IEEE Trans Ind 2023:1-10.
5. Zuo Z, Liu C, Han Q, Song J. Unmanned aerial vehicles: control methods and future challenges. IEEE/CAA J Autom Sinica 2022;9:601-14.
6. Liu Y, Zhan W, Xing M, Wu Y, Xu R, Wu X. Boundary control of a rotating and length-varying flexible robotic manipulator system. IEEE Trans Syst Man Cybern Syst 2022;52:377-86.
7. Hou Z, Xiong S. On model-free adaptive control and its stability analysis. IEEE Trans Automat Contr 2019;64:4555-69.
8. Wen G, Chen C, Ge S. Simplified optimized backstepping control for a class of nonlinear strict-feedback systems with unknown dynamic functions. IEEE Trans Cybern 2021;51:4567-80.
9. Fei J, Wang H, Fang Y. Novel neural network fractional-order sliding-mode control with application to active power filter. IEEE Trans Syst Man Cybern, Syst 2022;52:3508-18.
10. Li X, He J, Wen C, Liu X. Backstepping-Based adaptive control of a class of uncertain incommensurate fractional-order nonlinear systems with external disturbance. IEEE Trans Ind Electron 2022;69:4087-95.
11. Li Y, Hou Z, Che W, Wu Z. Event-Based design of finite-time adaptive control of uncertain nonlinear systems. IEEE Trans Neural Netw Learn Syst 2022;33:3804-13.
12. Ma J, Park J, Xu S. Command-Filter-Based finite-time adaptive control for nonlinear systems with quantized input. IEEE Trans Automat Contr 2021;66:2339-44.
13. Huang J, Wang W, Zhou J. Adaptive control design for underactuated cranes with guaranteed transient performance: theoretical design and experimental verification. IEEE Trans Ind Electron 2022;69:2822-32.
14. Lai G, Tao G, Zhang Y, Liu Z. Adaptive control of noncanonical neural-network nonlinear systems with unknown input dead-zone characteristics. IEEE Trans Neural Netw Learn Syst 2020;31:3346-60.
15. Duan G. High-order fully actuated system approaches: Part Ⅰ. Models and basic procedure. Int J Syst Sci 2021;52:422-35.
16. Duan G. High-order fully actuated system approaches: Part Ⅱ. Generalized strict-feedback systems. Int J Syst Sci 2021;52:437-54.
17. Duan G. High-order fully actuated system approaches: Part Ⅲ. Robust control and high-order backstepping. Int J Syst Sci 2021;52:952-71.
18. Duan G. High-order fully actuated system approaches: Part Ⅳ. Adaptive control and high-order backstepping. Int J Syst Sci 2021;52:972-89.
19. Duan G. High-order fully actuated system approaches: Part Ⅴ. Robust adaptive control. Int J Syst Sci 2021;52:2129-43.
20. Liu W, Duan G, Hou M. Concurrent learning adaptive command filtered backstepping control for high-order strict-feedback systems. IEEE Trans Circuits Syst Ⅰ 2023;70:1696-709.
21. Lu S, Tsakalis K, Chen Y. Development and application of a novel high-order fully actuated system approach-part Ⅰ: 3-DOF quadrotor control. IEEE Control Syst Lett 2023;7:1177-82.
22. Zhang D, Liu G, Cao L. Constrained cooperative control for high-order fully actuated multiagent systems with application to air-bearing spacecraft simulators. IEEE/ASME Trans Mechatron ; doi: 10.1109/10.1109/tmech.2022.3223927.
23. Zhang D, Liu G, Cao L. Proportional integral predictive control of high-order fully actuated networked multiagent systems with communication delays. IEEE Trans Syst Man Cybern Syst 2023;53:801-12.
24. Lian Z, Shi P, Lim C, Yuan X. Fuzzy-Model-Based lateral control for networked autonomous vehicle systems under hybrid cyber-attacks. IEEE Trans Cybern 2023;53:2600-9.
25. Pan Y, Wu Y, Lam H. Security-Based Fuzzy control for nonlinear networked control systems with dos attacks via a resilient event-triggered scheme. IEEE Trans Fuzzy Syst 2022;30:4359-68.
26. Zhang X, Han Q, Ge X, et al. Networked control systems: a survey of trends and techniques. IEEE/CAA J Autom Sinica 2020;7:1-17.
27. Jiang B, Karimi H, Kao Y, Gao C. Takagi-Sugeno model based event-triggered fuzzy sliding-mode control of networked control systems with semi-markovian switchings. IEEE Trans Fuzzy Syst 2020;28:673-83.
28. Peng C, Sun H. Switching-Like event-triggered control for networked control systems under malicious denial of service attacks. IEEE Trans Automat Contr 2020;65:3943-9.
29. Wang J, Yang C, Xia J, Wu Z, Shen H. Observer-Based sliding mode control for networked fuzzy singularly perturbed systems under weighted try-once-discard protocol. IEEE Trans Fuzzy Syst 2022;30:1889-99.
30. Chen G, Sun J, Chen J. Passivity-Based robust sampled-data control for markovian jump systems. IEEE Trans Syst Man Cybern Syst 2020;50:2671-84.
31. Chen G, Xia J, Park J, Shen H, Zhuang G. Sampled-Data synchronization of stochastic markovian jump neural networks with time-varying delay. IEEE Trans Neural Netw Learn Syst 2022;33:3829-41.
32. Xia J, Chen G, Park J, Shen H, Zhuang G. Dissipativity-Based sampled-data control for fuzzy switched markovian jump systems. IEEE Trans Fuzzy Syst 2021;29:1325-39.
33. Zou Y, Zuo Z, Xia K, Basin M. Saturated Sampled-data distributed control for interval consensus of multi-agent systems. IEEE Trans on Signal and Inf Process over Networks 2022;8:1024-36.
34. Huang J, Wang W, Wen C, Li G. Adaptive event-triggered control of nonlinear systems with controller and parameter estimator triggering. IEEE Trans Automat Contr 2020;65:318-24.
35. Zhang J, Li S, Xiang Z. Adaptive fuzzy output feedback event-triggered control for a class of switched nonlinear systems with sensor failures. IEEE Trans Circuits Syst Ⅰ 2020;67:5336-46.
36. Zhang J, Li S, Xiang Z. Adaptive event-triggered control of uncertain nonlinear systems using intermittent output only. IEEE Trans Automat Contr 2022;67:4218-25.
37. Wang X, Xia J, Park J, Xie X, Chen G. Intelligent control of performance constrained switched nonlinear systems with random noises and its application: an event-driven approach. IEEE Trans Circuits Syst Ⅰ 2022;69:3736-47.
38. Wang X, Xia J, Park J, Xie X, Chen G. Event-Triggered adaptive tracking with guaranteed transient performance for switched nonlinear systems under asynchronous switching. IEEE Trans Cybern 2023; doi: 10.1109/tcyb.2022.3223983.
39. Meng R, Hua C, Li K, Ning P. A multifilters approach to adaptive event-triggered control of uncertain nonlinear systems with global output constraint. IEEE Trans Cybern 2023; doi: 10.1109/tcyb.2022.3190861.
40. Meng R, Hua C, Li K, Ning P. Adaptive event-triggered control for uncertain high-order fully actuated system. IEEE Trans Circuits Syst Ⅱ 2022;69:4438-42.
41. Yang D, Zong G, Su S. H∞ Tracking control of uncertain markovian hybrid switching systems: a fuzzy switching dynamic adaptive control approach. IEEE Trans Cybern 2020;52:3111-22.
42. Chen H, Zong G, Gao F, Shi Y. Probabilistic event-triggered policy for extended dissipative finite-time control of mjss under cyber-attacks and actuator failures. IEEE Trans Automat Contr 2023; doi: 10.1109/tac.2023.3246429.
Cite This Article
Export citation file: BibTeX | RIS
OAE Style
Yan C, Xia J, Liu X, Yue H, Li C. Adaptive backstepping control of high-order fully actuated nonlinear systems with event-triggered strategy. Intell Robot 2023;3(2):176-89. http://dx.doi.org/10.20517/ir.2023.11
AMA Style
Yan C, Xia J, Liu X, Yue H, Li C. Adaptive backstepping control of high-order fully actuated nonlinear systems with event-triggered strategy. Intelligence & Robotics. 2023; 3(2): 176-89. http://dx.doi.org/10.20517/ir.2023.11
Chicago/Turabian Style
Yan, Chengyuan, Jianwei Xia, Xinru Liu, Huarong Yue, Chong Li. 2023. "Adaptive backstepping control of high-order fully actuated nonlinear systems with event-triggered strategy" Intelligence & Robotics. 3, no.2: 176-89. http://dx.doi.org/10.20517/ir.2023.11
ACS Style
Yan, C.; Xia J.; Liu X.; Yue H.; Li C. Adaptive backstepping control of high-order fully actuated nonlinear systems with event-triggered strategy. Intell. Robot. 2023, 3, 176-89. http://dx.doi.org/10.20517/ir.2023.11
About This Article
Special Issue
Copyright

Data & Comments
Data
0


 Cite This Article 8 clicks
Cite This Article 8 clicks

 Like This Article 4
likes
Like This Article 4
likes







Comments
Comments must be written in English. Spam, offensive content, impersonation, and private information will not be permitted. If any comment is reported and identified as inappropriate content by OAE staff, the comment will be removed without notice. If you have any queries or need any help, please contact us at support@oaepublish.com.